A database pod fails. Instead of panic, the cluster automatically provisions a new node and rebalances data to restore a healthy state—all without human intervention.
#1about 3 minutes
The evolution of running databases in containers
The community's perspective shifted from advising against running databases in containers to embracing it due to improvements in Docker and the rise of Kubernetes.
#2about 1 minute
Challenges of a naive database deployment on Kubernetes
A simple deployment of a database like MySQL on Kubernetes creates configuration management problems and requires maintaining multiple container images.
#3about 5 minutes
Using custom resource definitions to manage configuration
Custom Resource Definitions (CRDs) extend the Kubernetes API, allowing you to store application-specific configuration directly within the cluster.
#4about 4 minutes
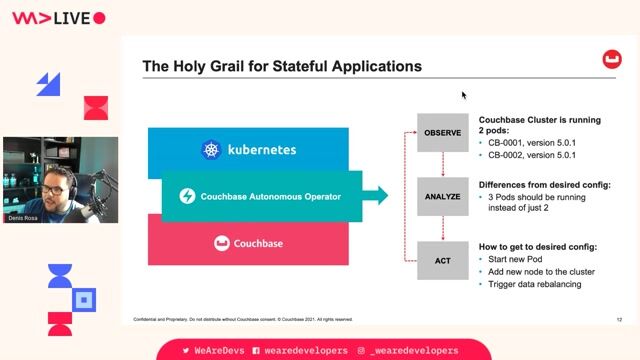
Understanding stateful application failures in Kubernetes
Standard Kubernetes deployments fail to manage stateful applications like databases because they don't handle node failures, pod affinity, or state recovery automatically.
#5about 5 minutes
The Kubernetes operator pattern for database automation
The operator pattern uses custom controllers to listen for events and encode operational knowledge, automating complex tasks like database recovery and upgrades.
#6about 10 minutes
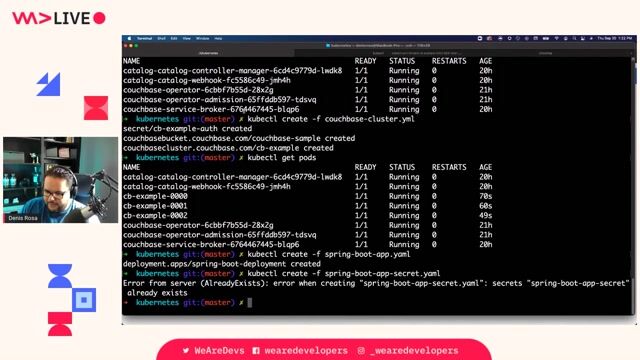
Live demo of the Couchbase operator in action
The Couchbase operator demonstrates self-healing by automatically replacing a deleted pod, rejoining it to the cluster, and rebalancing data without manual intervention.
#7about 7 minutes
Scaling and upgrading a database with an operator
Operators simplify complex operations like scaling out nodes, performing rolling upgrades, and tuning resource allocation by just modifying a declarative configuration file.
#8about 3 minutes
Comparing managed DBaaS with databases on Kubernetes
While managed DBaaS is simpler for small workloads, running databases on Kubernetes with operators provides greater flexibility, control, and cost-effectiveness at scale.
#9about 4 minutes
Storage and performance considerations on Kubernetes
Using local persistent storage is recommended for performance, and benchmarks show only a minimal 3-4% overhead when running databases in containers versus bare metal.
#10about 1 minute
Key takeaways for running databases on Kubernetes
When running databases on Kubernetes, choose a mature operator, prefer local persistent storage, and account for a small performance overhead compared to bare metal.
Related jobs
Jobs that call for the skills explored in this talk.
Why Attend a Developer Event?Modern software engineering moves too fast for documentation alone. Attending a world-class event is about shifting from tactical execution to strategic leadership.
Skill Diversification: Break out of your specific tech stack to see how the industry...
Learning Kubernetes made easy with KubeCampusLearning to use Kubernetes? KubeCampus by Kasten offers free educational content for all skill levels to get you started!Kubernetes is an open-source system for deploying, scaling and managing containerized applications. It allows you to deploy your ...