How do you run fast aggregations on distributed data? See how Elasticsearch trades tiny accuracy for massive speed gains.
#1about 3 minutes
Understanding the benefits of distributed systems
Distributed systems offer advantages like load sharing, increased reliability through redundancy, and faster processing via parallelization.
#2about 5 minutes
Navigating the complexities of distributed computing
Moving from a single machine to a distributed environment introduces significant complexity in communication, coordination, and error handling, as highlighted by the fallacies of distributed computing.
#3about 3 minutes
How distributed systems achieve consensus
Consensus algorithms are crucial for maintaining a consistent state across all nodes, enabling tasks like cluster membership management, data writes, and leader election.
#4about 4 minutes
Introducing the core principles of Elasticsearch
Elasticsearch is a distributed search engine built for speed, scale, and relevance, offering resiliency and flexibility for use cases from e-commerce to observability.
#5about 5 minutes
Managing the cluster with a master node
Elasticsearch uses a master node to manage the cluster state, which includes node membership and data placement, and distributes this state to all nodes to ensure a consistent view.
#6about 3 minutes
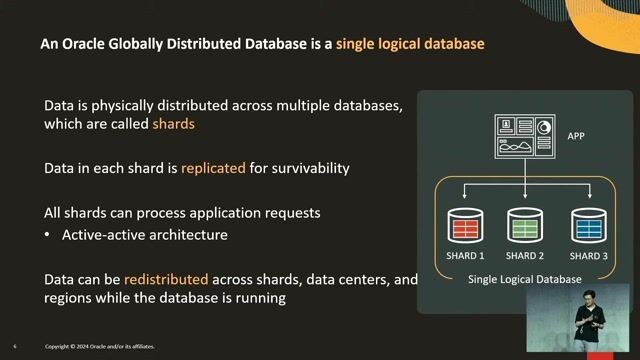
Distributing data using shards and replicas
Data in Elasticsearch is partitioned into shards, with replica shards providing redundancy and read scalability, allowing the system to scale horizontally.
#7about 2 minutes
Understanding the two-phase distributed search process
A search request is handled in two phases, first querying all relevant shards for top results and then fetching the full documents from only the necessary shards.
#8about 1 minute
Optimizing query routing with adaptive replica selection
Instead of random routing, adaptive replica selection improves query performance by sending requests to shards on less busy nodes based on their recent response times.
#9about 3 minutes
Accelerating top-k queries with result skipping
Search performance can be dramatically improved by dynamically optimizing queries to skip documents that cannot possibly make it into the top results, at the cost of an exact total hit count.
#10about 3 minutes
Navigating the challenges of distributed aggregations
Calculating aggregations like term counts across distributed shards is complex and can lead to inaccuracies if not all data is considered, requiring careful handling of partial results.
#11about 3 minutes
Efficient aggregations with probabilistic data structures
Probabilistic data structures like HyperLogLog++ and T-Digest enable memory-efficient cardinality and percentile aggregations by trading perfect accuracy for significantly reduced resource usage.
#12about 5 minutes
Embracing trade-offs in distributed system design
Building and operating distributed systems involves accepting trade-offs between consistency, availability, and performance, making it crucial to understand the specific behaviors of your chosen system.
#13about 6 minutes
Answering questions on Elasticsearch internals
The Q&A session covers Elasticsearch's custom consensus algorithm, data placement using MurmurHash, and the role of tokenizers in text analysis.
Related jobs
Jobs that call for the skills explored in this talk.
Why Attend a Developer Event in 2026?Modern software engineering moves too fast for documentation alone. Attending a world-class developer event is about shifting from tactical execution to strategic leadership — and in 2026, the opportunity to do that on US soil has never been stronger...
Chris Heilmann
WeAreDevelopers Dev Digest Issue 116 - The new search wars…Welcome to edition 116 of the WeAreDevelopers Dev Digest. This time we talk about how the fight for AI and search dominance heats up with Google releasing a lot at their I/O event and OpenAI doing the same a day earlier…News and ArticlesA ton of thin...